 |  |

1.01 (2008/03/29)
Jiten FAQCan I change the British flag for the one of my own country?
Yes! Here is an example flag. The dark green represents the 'transparent' part.  And when set up as 'myflag.ico', the "Language" part of the main window will now look like:  To make things easier for you, some library flags are provided within Jiten. There are flags for Australia, Canada, New Zealand, and the United States. Simply rename as appropriate.
How many words are in the dictionaries? There are 64,150 Japanese words cross-referenced with 104,694 English words. This is because many words do not have a 1:1 relationship. If you look up the Japanese word kokoro you will see that it can mean mind or body or spirit, now looking up spirit (exactly) as an English word will give you 43 possible Japanese words that can mean spirit (of which kokoro is ninth). The master dictionary table contains 71,511 entries.
I wanted to look at the dictionary data, and now Jiten mucks up or crashes, why?
You probably used a text editor that does not fully understand files where lines are not terminated in Windows CRLF format - the Jiten data files are stored according to RISC OS conventions.
Is it possible to remove rude words from the dictionary? No, not without completely rebuilding the main dictionary and the associated references.
However, if you edit the shortcut that loads Jiten to include the command line option
To edit the shortcut, right-click it. A menu with lots of options will appear. Choose the Properties option at the bottom of the menu. 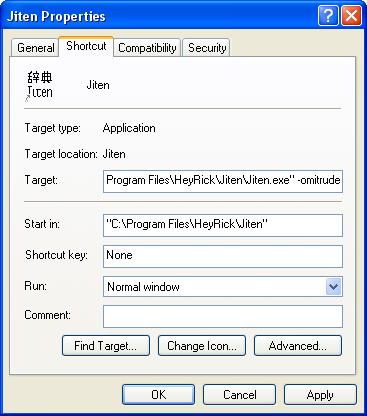 Go to the "Target" and append the text " -omitrude" (as shown). Click on OK. Now, whenever a rude word is looked up, the definitions will be hidden, like this: 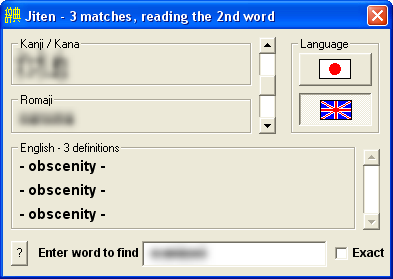 Please note that this only works when starting Jiten from the shortcut that you edit. If you have it as a shortcut on the 'backdrop', you'll need to edit that as well. It isn't foolproof by any means, however I feel that a child smart enough to find and start the program without using the shortcuts (assuming your system policy has not disabled the "Explorer" and "Run" commands) will probably have better things to do than learn how to say rude words in Japanese... after all, you do filter external internet access don't you? ☺
Why can't I type numbers into the search box? In the writeable text area where you enter what you wish to look for:
Where did the dictionary come from? As credited in the help file:
Say I have a later version of !Jiten, how do I update the dictionaries? The dictionary data was sourced from Philip's !Jiten version 1.01 dated 1998/08/12. To update, perform the following file copies, noting that Jiten is installed at:
Then delete the files english.table and romaji.table.
When you next start Jiten, it will rebuild the data tables. This process can take two to five minutes, depending on the speed of your computer.
Is it possible to build the data from the EDICT file? At this time, no. I will look to downloading the EDICT (if it is still around? I don't have Internet at home...) and see what would be required to build the data tables directly from the source material.
Any Easter Eggs? Of course! ☺
Perhaps the most useful is if you provide the command line option What this does is attempt to translate the "wordprocessor style" Romaji into a nicer form. Thus meaning that "toukyou" would become "tôkyô" and "se-ra-fuku" would become "sêrâfuku". It is not possible to display the macron (i.e. "tōkyō", if your browser supports it), so a circumflex is used in its place, like this: 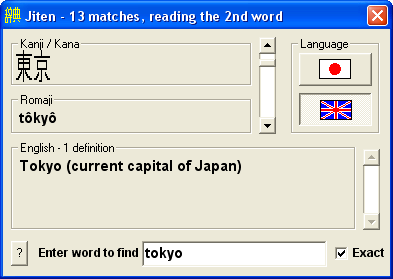 The translation logic is:
This list was determined by comparing a source with proper Hepburn markings with various words in the dictionary; sadly the Wiki entry for Hepburn Romanisation does not have a definitive list; therefore if this is incorrect or incomplete, please contact me. Please note that this munging is a one-way process, you must enter words to search for in the wordprocessor style (i.e. "toukyou" in Japanese, not "tokyo").
I found your info easter egg. Why is the dictionary in memory so much bigger than on disc? You mean you found this (scaled to save space):  The reason for the size disparity with the table is that when on disc, string data is stored in ANSI format. That is to say that "cute" is However when the data is loaded into memory, it is translated into Unicode format. That is to say that "cute" now would be I suppose this might be reasonable, except not only can VisualBasic 5 not display characters outside of the standard code page (i.e. characters 32 to 255), it also communicates with Windows using the ANSI versions of the API so all of the strings, internally held as Unicode, need to be munged into ANSI versions before getting Windows to do anything.
Between you and me, I think this bogosity is because VB went Unicode a long time before Windows did. Only a small subset of functions are Unicode on WIN32 (that is, Windows 95, 98(SE), and ME). In that era, extended languages such as Japanese were represented with DBCS (double-byte character string). It wasn't until XP hit the mass market that a properly Unicode-aware version of Windows was available. |